В третьей части разберем основной современный метод прогноза LTV — с помощью машинного обучения.
25 мая 2022
Гайд по LTV, третья часть: прогноз метрики с помощью машинного обучения (для онлайн- и офлайн-бизнесов)

В первой части гайда мы разобрали основы — что такое LTV и зачем он нужен, какие индустрии выиграют, если будут анализировать LTV, как рассчитывать метрику с помощью классического валового метода. Во второй части рассмотрели разницу между валовыми методами расчета и историческим LTV, показали формулы для расчета метрики, а также выяснили, как собрать данные и выбирать метод расчета.
В третьей части разберем основной современный метод прогноза LTV — с помощью машинного обучения. Рассмотрим по шагам на примере проекта для United Colors of Benetton и ASOS, как использовать этот продвинутый метод расчета.
Зачем считать LTV с помощью машинного обучения
В общем виде расчет и мониторинг LTV позволяет понять текущую ценность клиентской базы и динамику ее развития. Однако имея посчитанный показатель для конкретного клиента или сегмента (когорты), бизнес понимает, на каких каналах, сообщениях, локациях, коллекциях лучше сделать акцент для привлечения наиболее доходной категории покупателей, сколько можно тратить на привлечение новых и удержание старых клиентов в каждой точке своего присутствия.

На какие вопросы помогает ответить LTV, посчитанный до отдельного клиента
Мониторинг LTV также позволяет компаниям увидеть, что необходимо делать для увеличения показателя. Таким образом, расчет и мониторинг LTV помогает:
- находить новые источники знания о покупателях (1P- и 3P-данные),
- видеть пользу от AB-экспериментов,
- улучшать качество и использовать доступные данные,
- заниматься интеграцией новых офлайн- и онлайн-данных о поведении покупателей.
По нашим наблюдениям, сама идея работать с LTV уже повышает КПД бизнеса. Размышления о систематизации данных и о факторах, которые выявлены с помощью ML-модели и влияют на метрику, полезны для любого бизнеса.
Согласно исследованию LTV в СНГ, больше половины компаний использует валовый метод. Однако более 25% крупного бизнеса переходят именно на ML, что явно подтверждает обоснованность таких инвестиций.
Как рассчитать LTV с помощью машинного обучения
1. Начать системно собирать данные. Для этого надо сначала запустить программу лояльности, пусть даже самую простую, и начать агрегировать в базе данных информацию из разных источников. Например, данные о рекламных расходах, просмотренных товарах и категориях, об использовании баллов лояльности, о действиях в мобильном приложении.
2. Определить факторы, которые влияют на LTV сильнее всего. Это важный этап, его не получится скопировать или перенять у другого бизнеса, так как одни и те же атрибуты (особенности, фичи) могут по-разному влиять на LTV в разных индустриях. Например, скидки положительно влияют на LTV в ритейле и негативно — в SaaS-продуктах.
Через 6–8 месяцев после того как вы начали собирать данные и определили факторы влияния, можно довольно точно предсказывать LTV. Если вы знаете ID клиента и понимаете, какие действия он совершает в онлайне и офлайне.
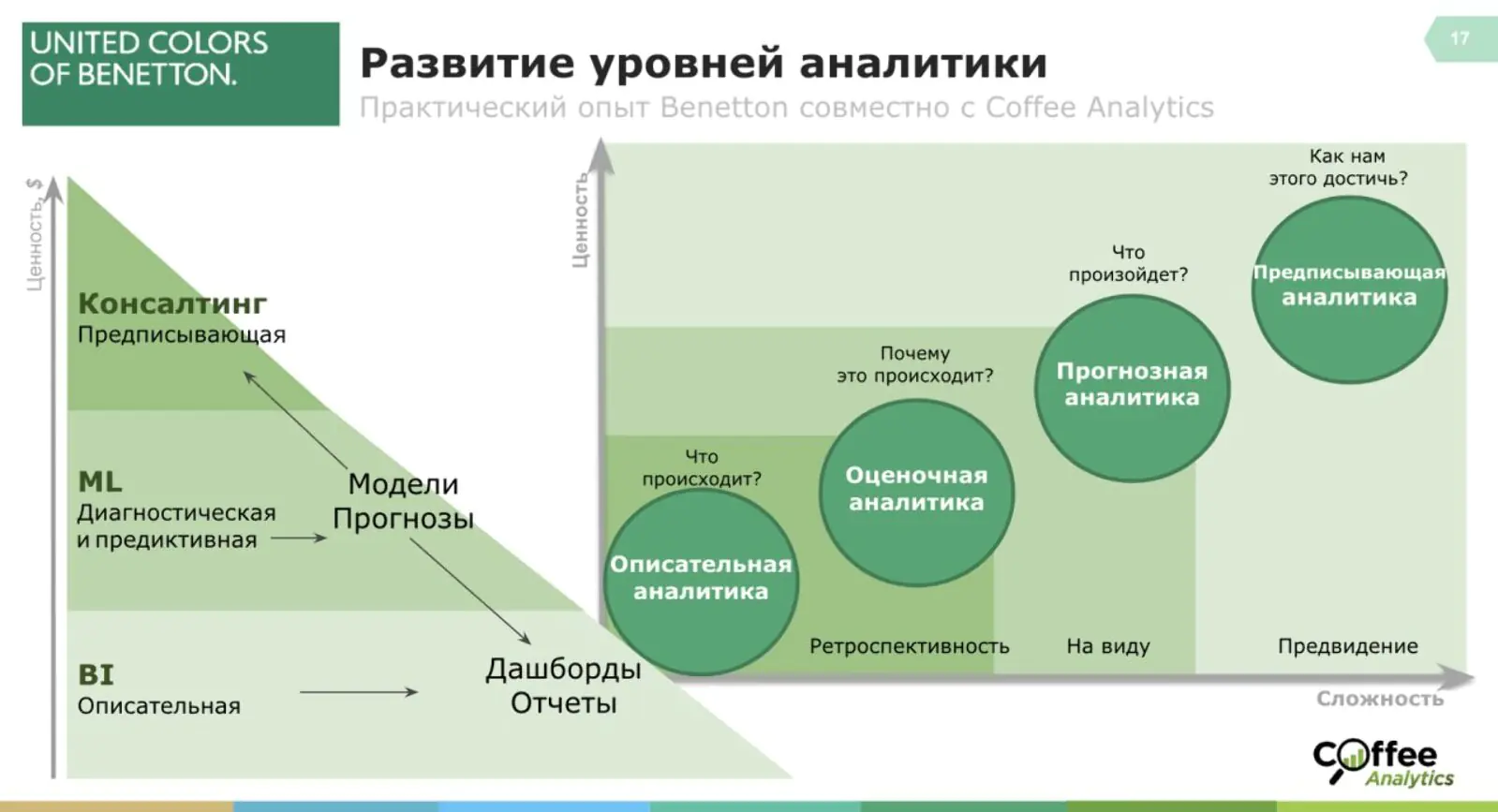
Подробнее о пользе прогнозной аналитики (куда входит и LTV-анализ как наиболее важный) в исследовании маркетинговой аналитике в СНГ. По мере роста отдачи от аналитики резко возрастает процент компаний, который использует LTV-анализ, корреляции, рассчитывает churn rate и определяет фрод. Синхронно уменьшается процент компаний, которые не используют прогнозную аналитику. Таким образом, чем сильнее уровень влияния аналитики, тем больше эти компании инвестируют в прогнозные и предписывающие методы:
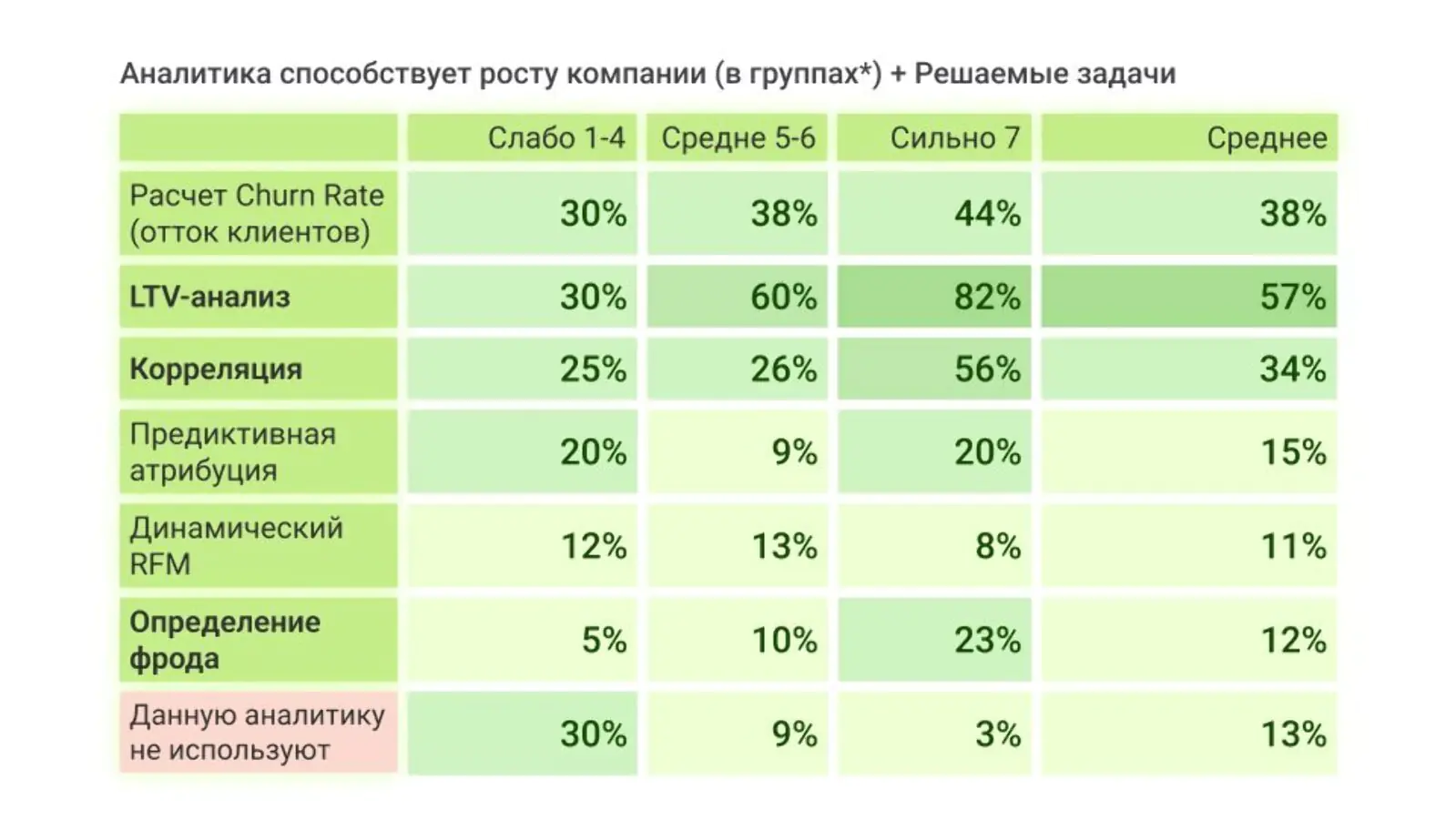
Фрагмент исследования Coffee Analytics о маркетинговой аналитике

Данные результаты очень хорошо иллюстрируют ситуацию в компаниях и на рынке специалистов: с ростом сложности инструментов падет их доля влияния. Так LTV-анализ имеет наибольшее влияние — он информативен и относительно легковыполнимый, при этом 2-3 место с большим отрывом занимает анализ оттока и корреляции и еще менее востребована предиктивная атрибуция, так как использование этих методов требует большей глубины и понимания полученных взаимосвязей.
Вероятно, это обосновано необходимостью высоких компетенций как в аналитике, так и в последующей интерпретации и внедрение полученных решений. А рынок испытывает дефицит квалифицированных кадров в области сложного анализа, соответственно не многие могут себе позволить подобные решения.
Как применять LTV на практике — кейс Benetton
United Colors of Benetton — крупный фэшн-бренд, у которого более 6000 магазинов по всему миру и более 120 в России. В конце 2018 года российское подразделение внедрило программу лояльности, которая начала бурно расти. Поэтому перед бизнесом встал вопрос о том, как грамотно оценить отдачу от этой программы и понять:
- какие дополнительные деньги может принести программа лояльности в будущем;
- сколько стоит привлечение нового клиента и сколько денег он принесет компании на протяжении следующего периода;
- какова ценность всей клиентской базы;
- от каких факторов зависит поведение клиента;
- как через эти факторы адаптировать весь маркетинг для работы с более доходными сегментами клиентов.
Сначала в Benetton считали доход с клиента, средний чек и количество покупок. Однако довольно быстро стало понятно, что эти метрики дают только понимание того, что уже произошло, а не того, что произойдет в будущем. Например, если у какого-либо сегмента падали продажи, эти показатели не объясняли, случайное это событие или тренд, который продолжится в будущем.
В итоге компания приняла решение считать LTV, опираясь на ML-подход. Проект запускали в пять этапов, модель собиралась в два шага, на каждом из которых использовались разные данные:
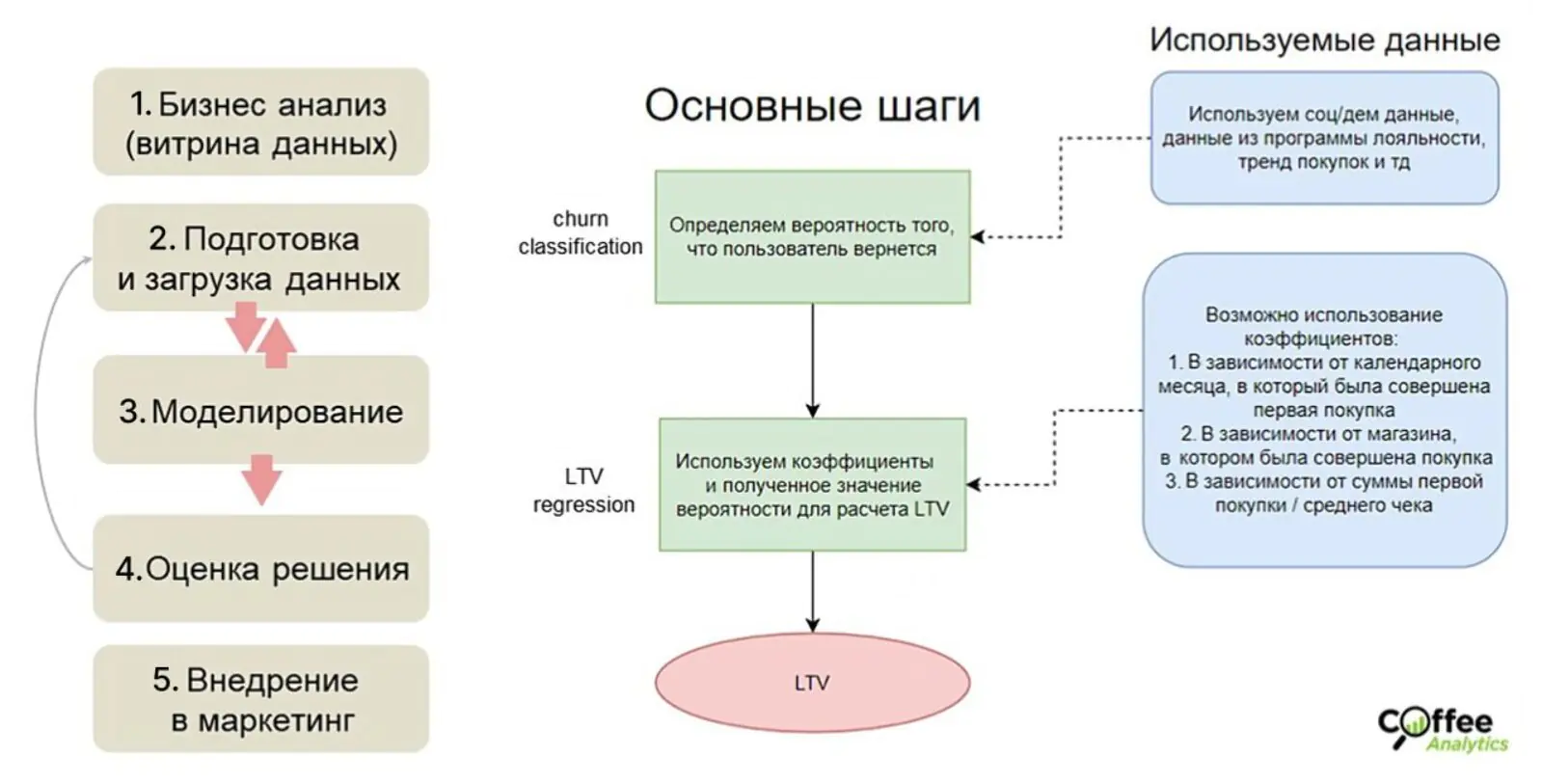
Стратегия расчета LTV Benetton
Реализовали стратегию расчета LTV, комбинируя две последовательные модели:
- Определили вероятность того, что клиент вернется в течение будущего года (churn classification).
- К клиентам с пороговой вероятностью возвращения применяли коэффициенты из финальной регрессионной модели и таким образом рассчитывали их LTV.
Далее расскажем о каждом этапе запуска расчета метрики.
Этапы 1–2. Подготовка витрины данных (все источники), бизнес-анализ
Собирали витрину данных из всех факторов, которые могут влиять на LTV:
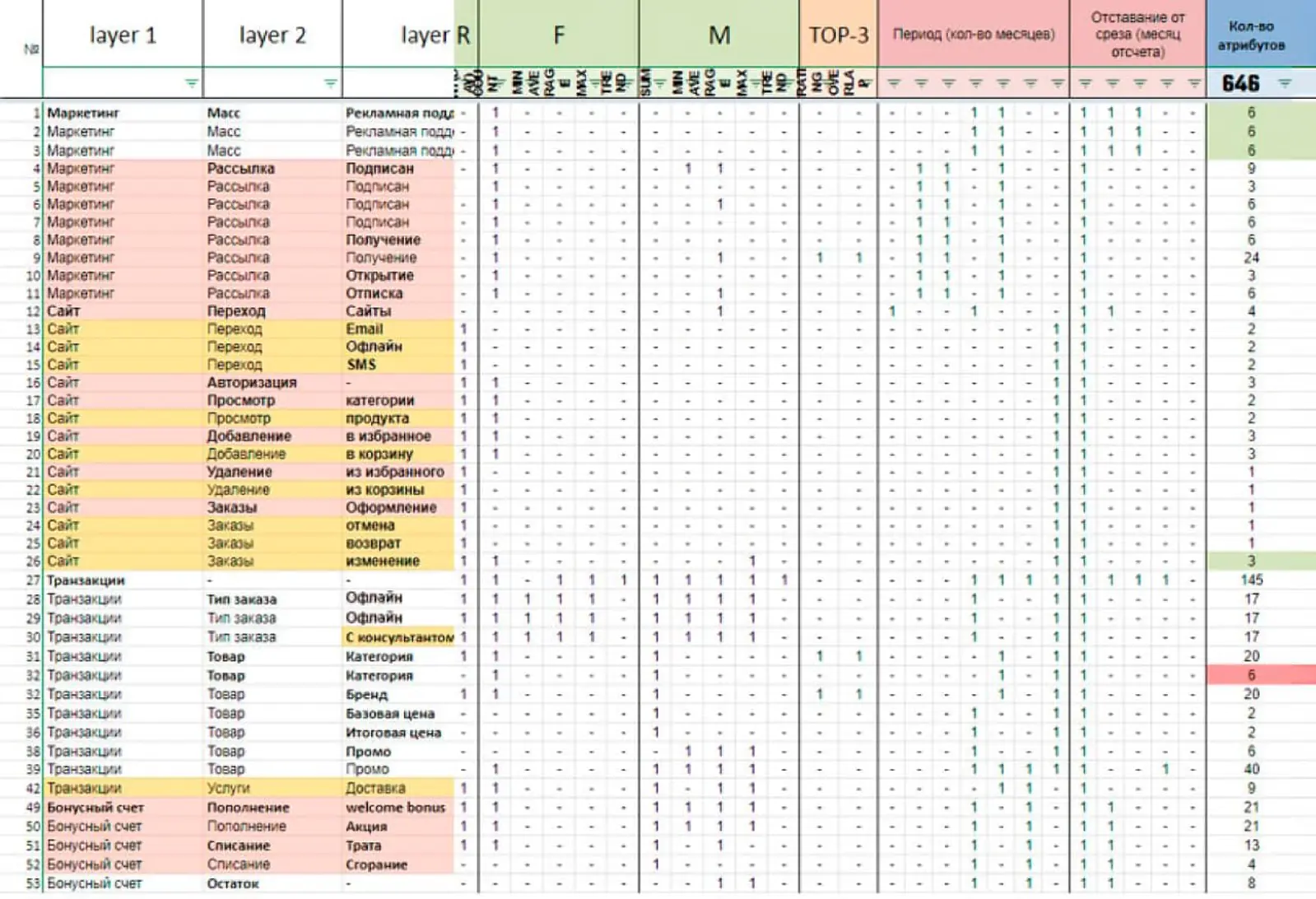
Пример витрины данных. Красным отмечены данные, которые точно есть, желтым — нужно начать собирать, белым — можно собирать, но на их подключение и сбор еще не поставлено ТЗ
Кроме того, для каждого фактора влияния подсчитывались максимальное, минимальное и медианное значения. Так, сначала для Benetton определили 646 атрибутов, которые способны влиять на LTV.
Параллельно с витриной готовили архитектуру данных проекта:
- На уровне CDP Mindbox фиксировались все данные по пользователям: транзакции, реакции на рассылки, действия в мобильном приложении и прочие.
- На уровне облачного хранилища данных (в данном случае Google BigQuery) фиксировались данные о рекламных расходах, данные со счетчиков на сайте и данные о трафике в магазинах.
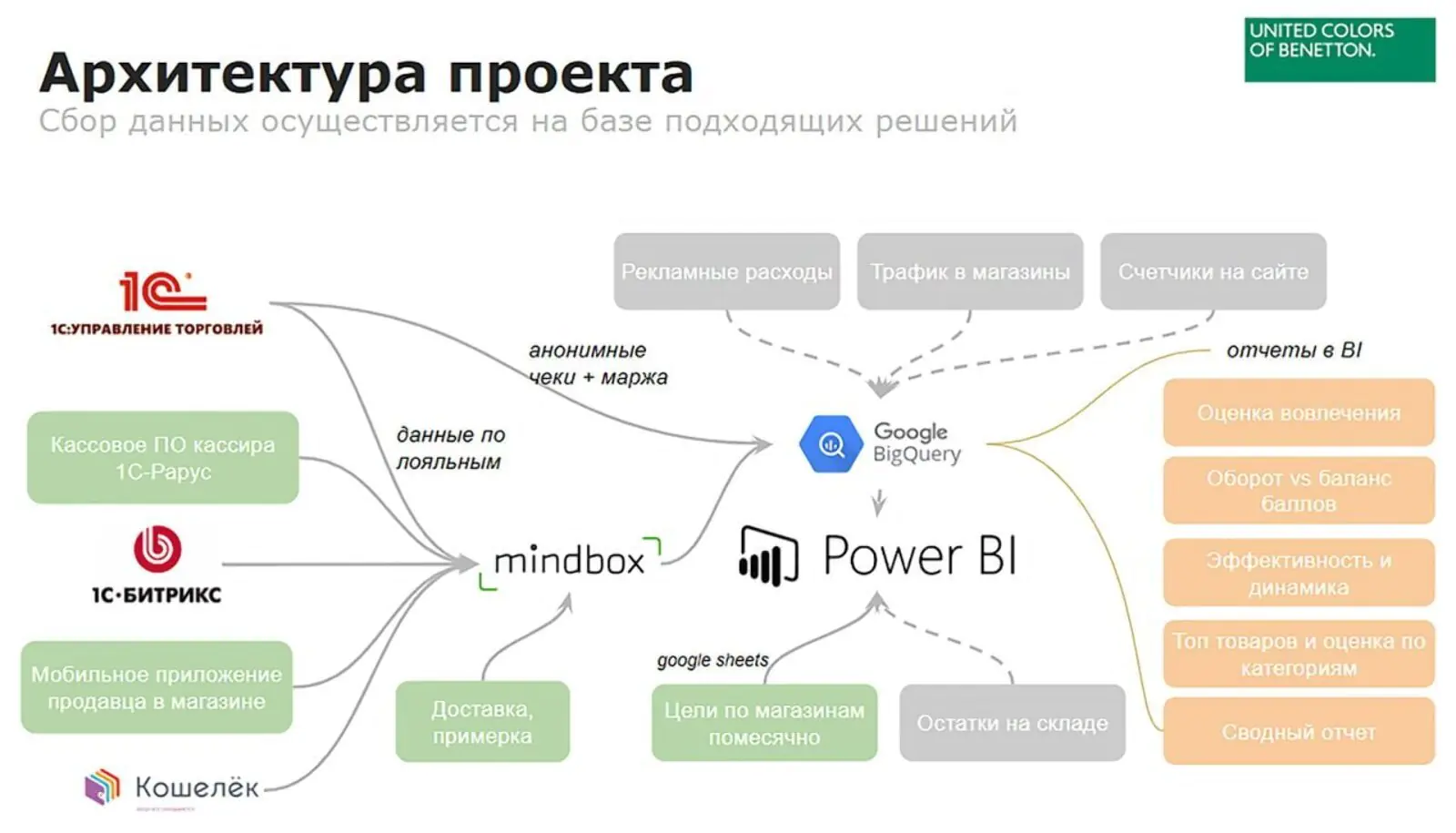
Архитектура данных Benetton
Потом эту архитектуру доработали и полученный LTV стали передавать в Mindbox. На основе этих данных в CDP построили сегменты пользователей, которые затем использовали для настройки промоактивностей. Заметим, что эту модель можно доработать и дальше — передавать LTV в рекламные кабинеты и таким образом влиять на приоритетность показа объявлений потенциальным клиентам (например, в ретаргетинге) и при формировании look-a-like сегментов.
Как Benetton соединил онлайн- и офлайн-данные для прогноза LTV:
Этап 3. Расчет показателя, моделирование
После подготовки витрины и архитектуры данных произвели расчет показателя. Для этого подготовили две модели: одна предсказывала churn rate, другая (с помощью регрессионного анализа) считала LTV.
Модель тренируется просто. Выборка данных за полный год делится на train- и test-датасеты. В первом известны реальные LTV клиентов, во втором нет. Модель тренируется на train и должна подобрать расчет, используя детали, максимально близкие к реальным LTV.
Далее оценивается качество прогноза на test-датасете путем сравнения расчетного LTV с реальным значением по клиенту. Процесс повторяется, пока не будет найдено решение с минимальной квадратичной суммой всех расхождений.
Получив это решение, можно делать прогноз, основанный на данных всех клиентов, пришедших за последний год и позднее, — то есть происходит внедрение модели и real-time-предсказание:
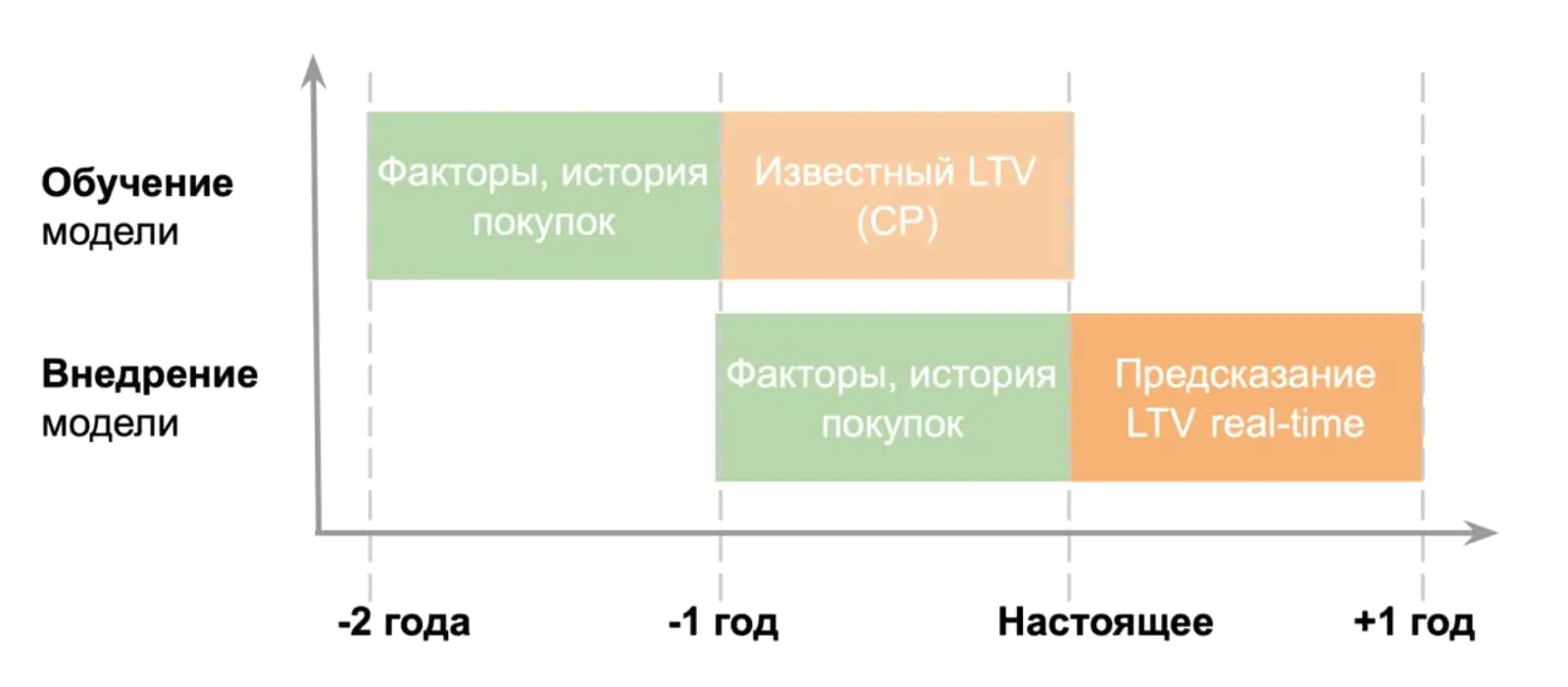
Стратегия расчета LTV
Этап 4. Оценка решения, улучшение модели
В качестве первого способа для определения важности использовалась модель линейной регрессии. Данные были стандартизированы для того, чтобы измеряемые величины не имели значения. Например, если будем сравнивать сумму, потраченную клиентом (рубли) и количество товаров (штуки), то из-за того, что для суммы используется другой порядок чисел, этот параметр окажет большее влияние. А стандартизация решает эту проблему.
Однако линейная регрессия плохо работает с большим количеством параметров (как в данном кейсе), поэтому далее применили алгоритм GBL, основанный на деревьях решений (decision trees). Результат был значительно лучше по всем метрикам качества.
Топ-20 фич для алгоритма GBL, после того как убрали высококоррелирующие (проверка на мультиколлинеарность):

Влияние одних и тех же факторов на LTV в разных видах бизнеса
У Benetton большая клиентская аудитория. Поэтому каждый день появлялся сегмент клиентов, которые ровно год назад вступили в программу лояльности. Данные таких клиентов автоматически отправлялись для обучения модели и улучшали качество предсказания LTV по новым потребителям.
После запуска модели началась вторая часть по расчету LTV — постоянная проверка того, какие еще данные можно добавить к модели. Если их находили, то добавляли в существующую модель, которая заново проводила оценку решения. После этого цикл возвращался к шагу поиска и подготовки новых данных. По сути, этот процесс не прекращается, и модель расчета LTV можно дорабатывать постоянно, чтобы получать более надежные результаты в метриках.
Финальная модель. Анализирует недельные когорты на определение LTV их клиентов. Учитывает все ключевые косвенные факторы (например, рекламные источники), которые в долгосрочной перспективе повлияли на совершенные в этот период покупки (годовой LTV). В результате уровень расхождения между предсказанием и фактическим значением в первые несколько месяцев постепенно снижался, хотя было еще мало данных (большинство клиентов зарегистрировались в программе лояльности 1–3 месяца назад). Далее с увеличением объема данных качество предсказания улучшается по всем когортам:
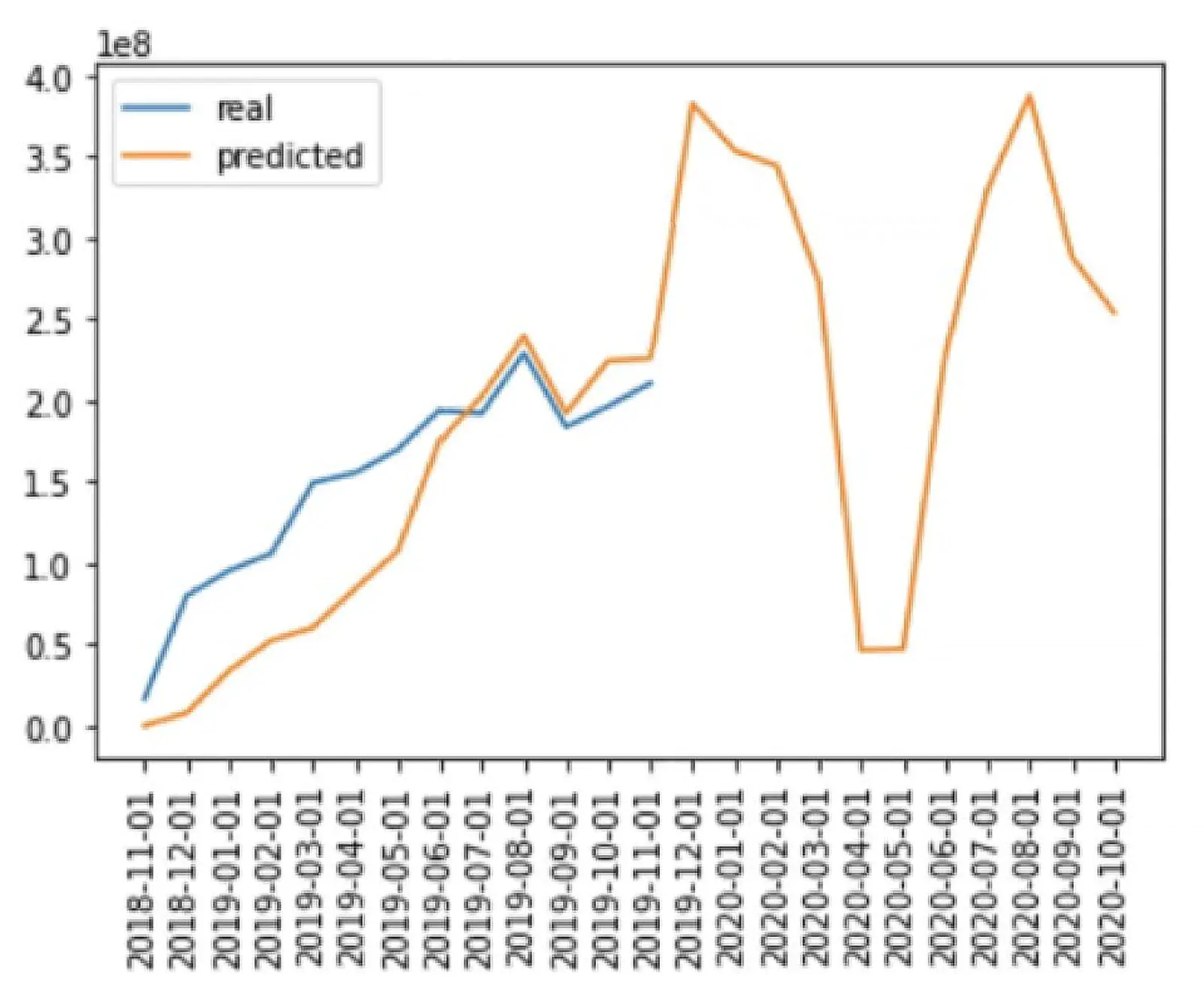
Также модель можно улучшать через:
- доработку churn-классификатора (вернется клиент или нет);
- внедрение разных коэффициентов для покупателей, начавших свою «жизнь» в один и тот же период.
Этап 5. Внедрение в маркетинг, визуализация отчетов в Power BI
После расчета и применения модели LTV построили несколько отчетов, которые United Colors of Benetton использует в следующих случаях:
- оценка эффективности программы лояльности;
- сегментация клиентской базы;
- качество работы акций;
- оценка рекламных кампаний.
Примеры отчетов LTV
LTV в динамике. Отчет об эффективности базы позволяет понять, сколько денег получит компания, даже если база не будет расти в течение года:
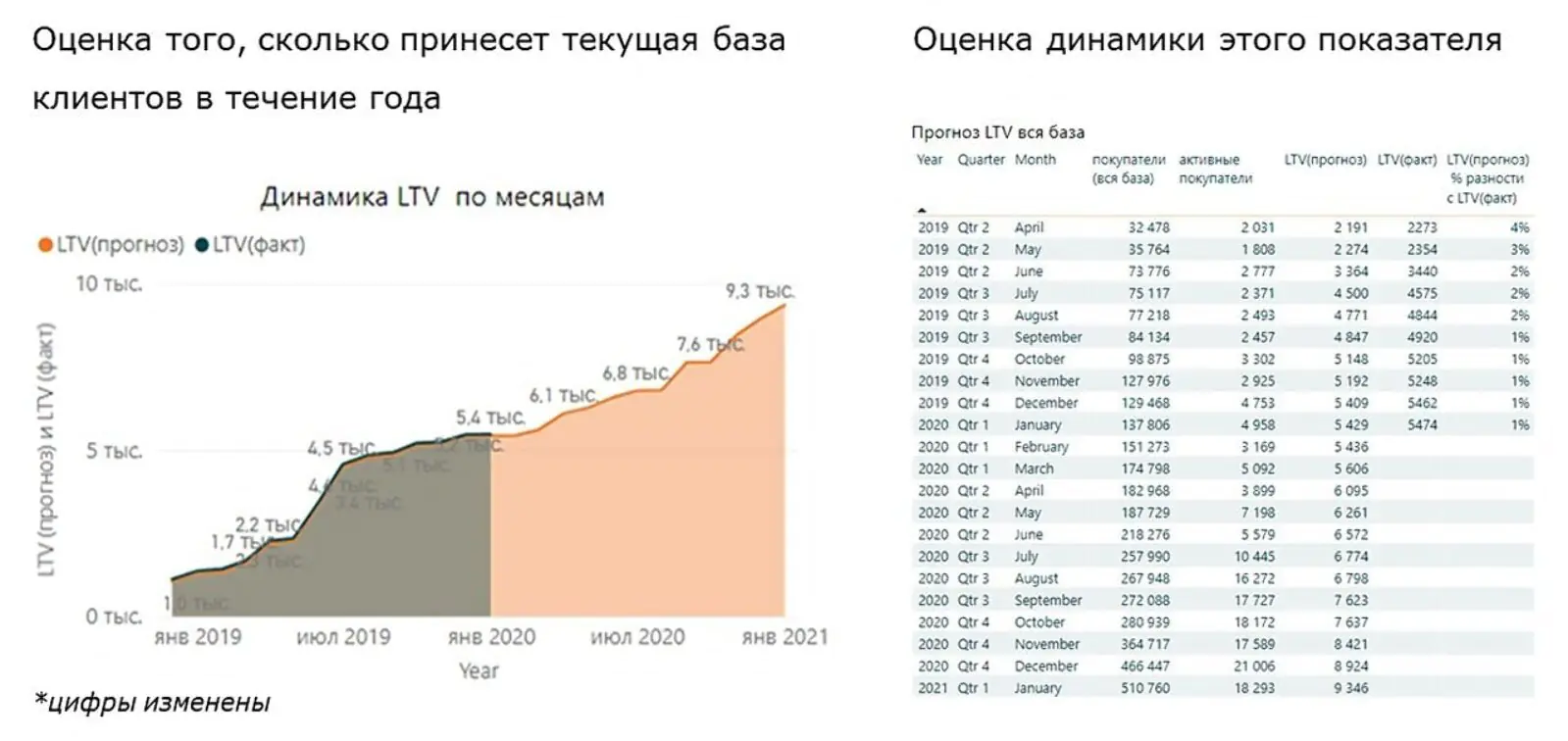
Факторы влияния на LTV. Отчет позволяет увидеть, почему какие-то клиенты приносят больше денег, чем другие. Показывает, как изменение одного фактора влияет на изменение LTV в целом:

Сегментация клиентской базы. После того как факторы влияния были определены, Benetton смог создавать кастомные сегменты и передавать их в Mindbox. Например, при помощи отчета по сегментации базы определили пользователей, наиболее склонных покупать новые коллекции, и запустили для них специальную рекламную кампанию:
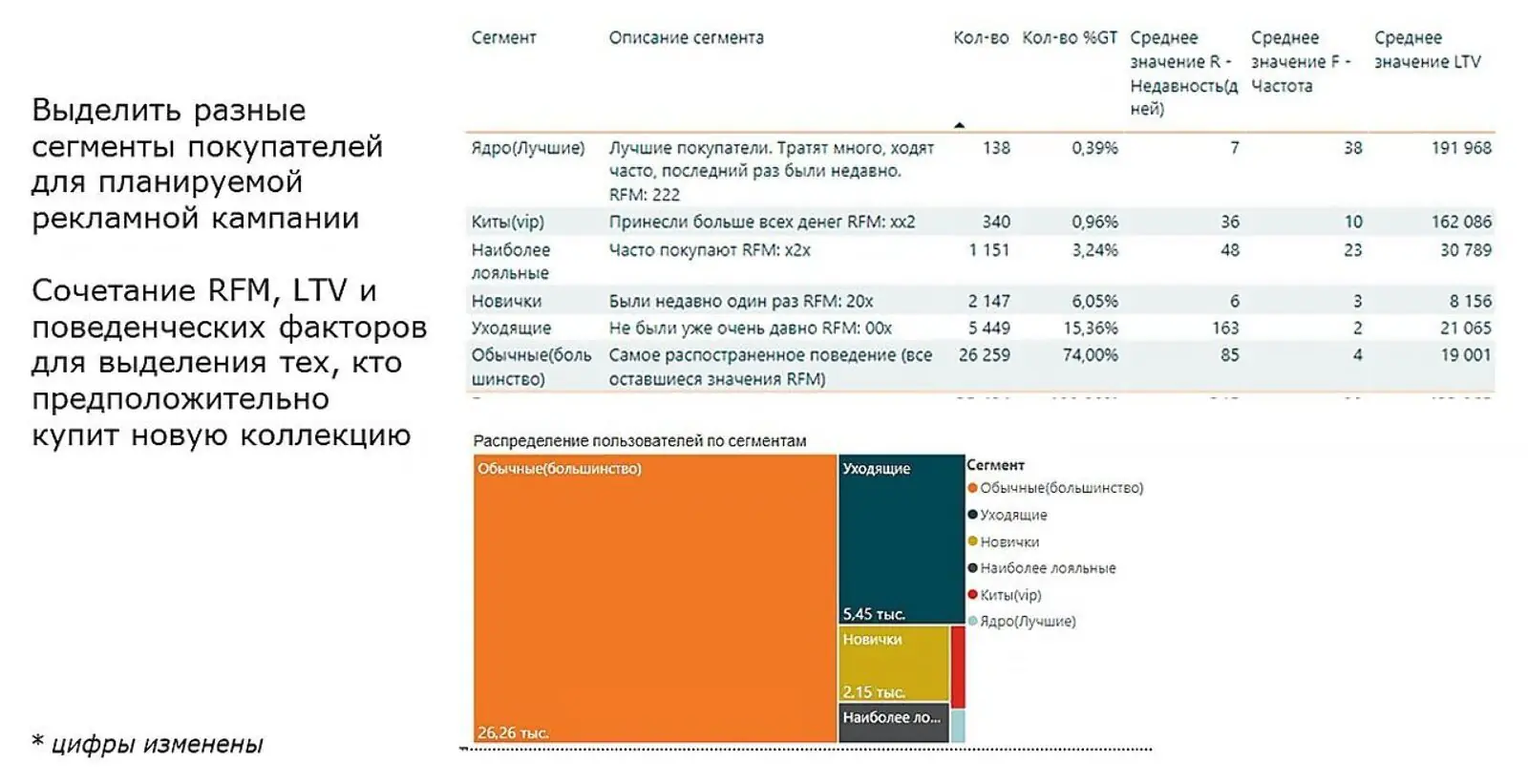
Когортный отчет с рекомендациями. Когортный анализ показал, что обычно лишь небольшая часть дохода генерируется новыми клиентами — понять это помог большой наплыв новых клиентов в четвертом квартале 2020 года. Старые клиенты (с первого квартала 2019 года) — самые стабильные. Кроме периода коронавирусных ограничений, они приносили бо́льшие суммы, чем клиенты, которые вступили в программу лояльности в другие периоды. Похоже, когорты клиентов, которые зарегистрировались в определенные кварталы, склонны проявлять наибольшую активность в эти же кварталы и в дальнейшем. Так выглядит оборот с клиентов, стартовавших в программе лояльности в разных кварталах 2018–2021 годов:
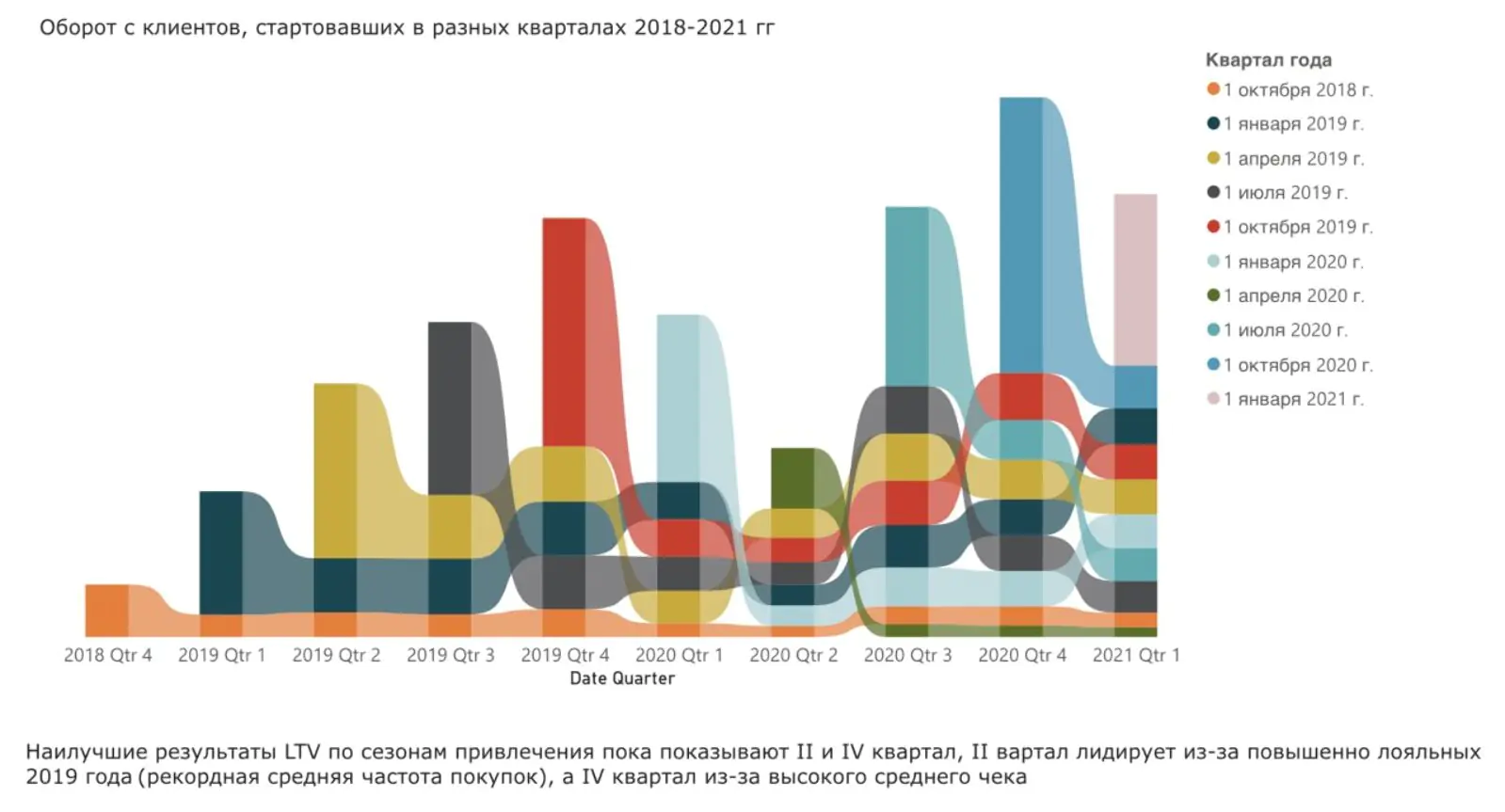
Таким образом, Benetton прошел весь цикл от описательной аналитики к предписывающей:
Benetton привязывает маркетинговые цели к изменению LTV. Например, цель во втором квартале — вырастить LTV на 5% и инвестировать для этого в рекламу и программу лояльности 5 млн рублей. (Цифры условны и не отражают реальности Benetton).
Реальный пример: для участников программы лояльности Benetton запустил игру «Барашек Джузеппе». Геймификация устроена так: после заказа клиент получает предложение сыграть → зарабатывает баллы в игре → тратит их в магазине на новые покупки.
Результаты игры «Барашек Джузеппе»:
-
5,6 ₽заработали на каждый потраченный на игру рубль
-
×1,5больше чеков у сегмента играющих клиентов
-
+2400 ₽выше LTV у игравших клиентов

Мы повышаем LTV через контроль размеров ключевых аудиторных сегментов (лучшие, лояльные, киты, новички, уходящие и т. д.) и характерного перетекания клиентов между ними.
Цель — при увеличении базы не снижать процент участников программы лояльности с покупками и увеличить процент покупателей, попадающих из активных в лучшие по характеристикам сегменты. Так мы добиваемся роста среднего LTV клиента на десятки процентов год к году.
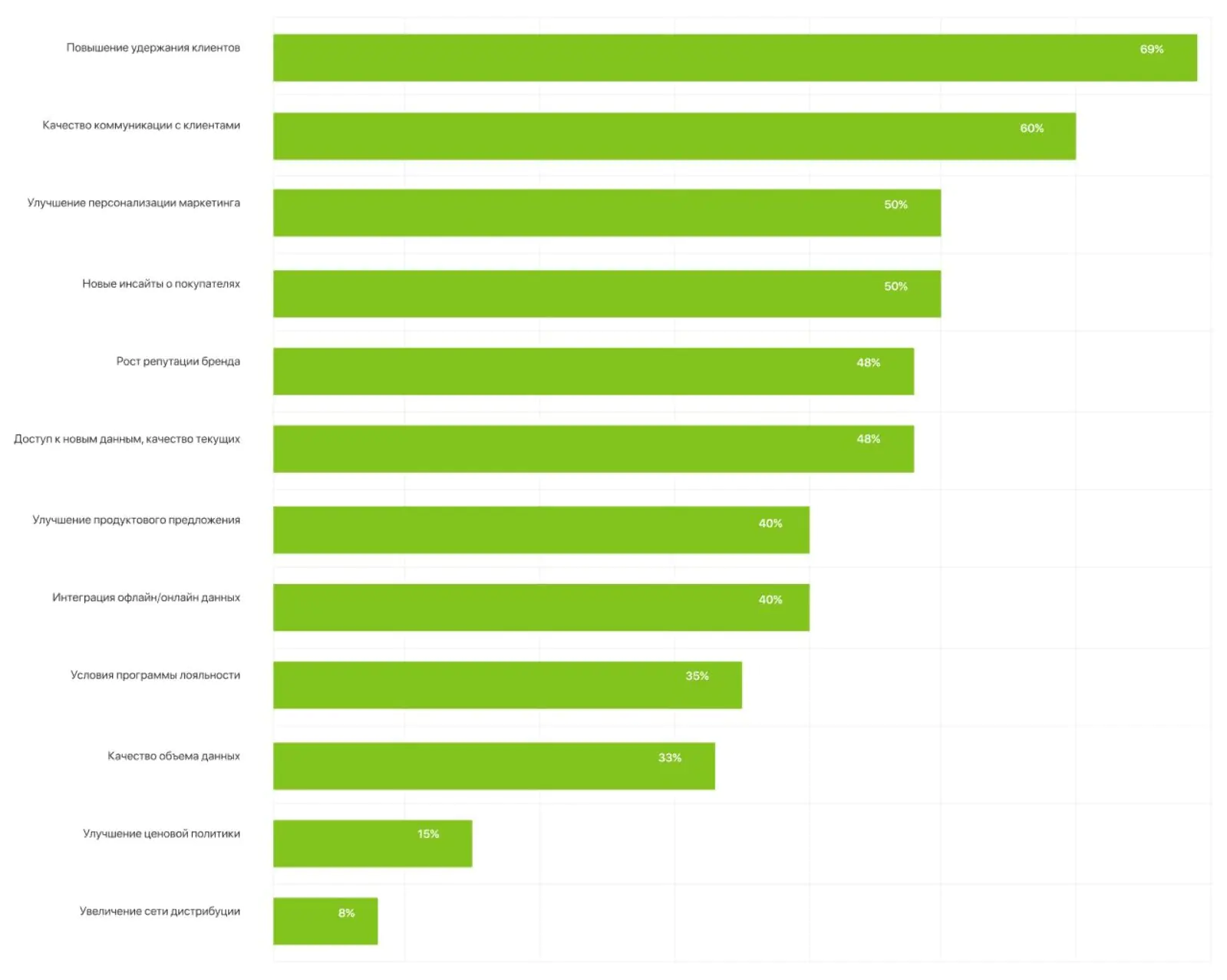
Такой подход совпадает с тем, как все индустрии планируют увеличить LTV. Согласно исследованию Coffee Analytics, удержание клиентов (retention) — наиболее популярный способ повысить LTV. Другие способы:
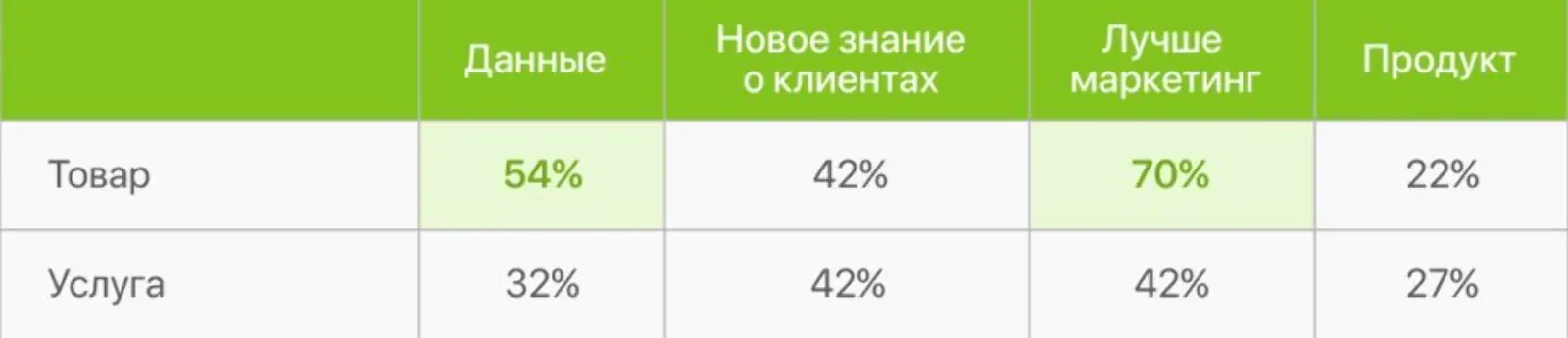
Особенно стоит отметить интерес товарных компаний к блокам «Данные» (54%) и «Лучше маркетинг» (70%) — это связано как с меньшей маржинальностью, так и с более высокой конкуренцией на рынках:
Кейс ASOS из Великобритании — высший пилотаж расчета LTV
Расчет LTV для компании ASOS создал Имперский колледж Лондона (Imperial College London). Этот кейс интересен тем, что архитектура проекта, помимо churn rate и регрессионной модели LTV, учитывает эмбединги (embedding — группировка слов, встречающихся в схожем контексте).
Вызовы ASOS
В компании действует бесплатная доставка и возврат, то есть легко получить отрицательный LTV клиента. Для снижения этих рисков компания поставила цель точно прогнозировать отток клиентов и считать LTV. Такая стратегия решения во многом схожа с кейсом Benetton.
Модель расчета каждый день «тренируется», используя новые данные за последние два года. Это позволяет учитывать сезонность данных. Обучение модели проходит в два этапа:
- Предобработка данных и обучение Random Forest для прогнозирования оттока и LTV.
- Калибровка данных (сопоставление процентилей с реальными значениями).
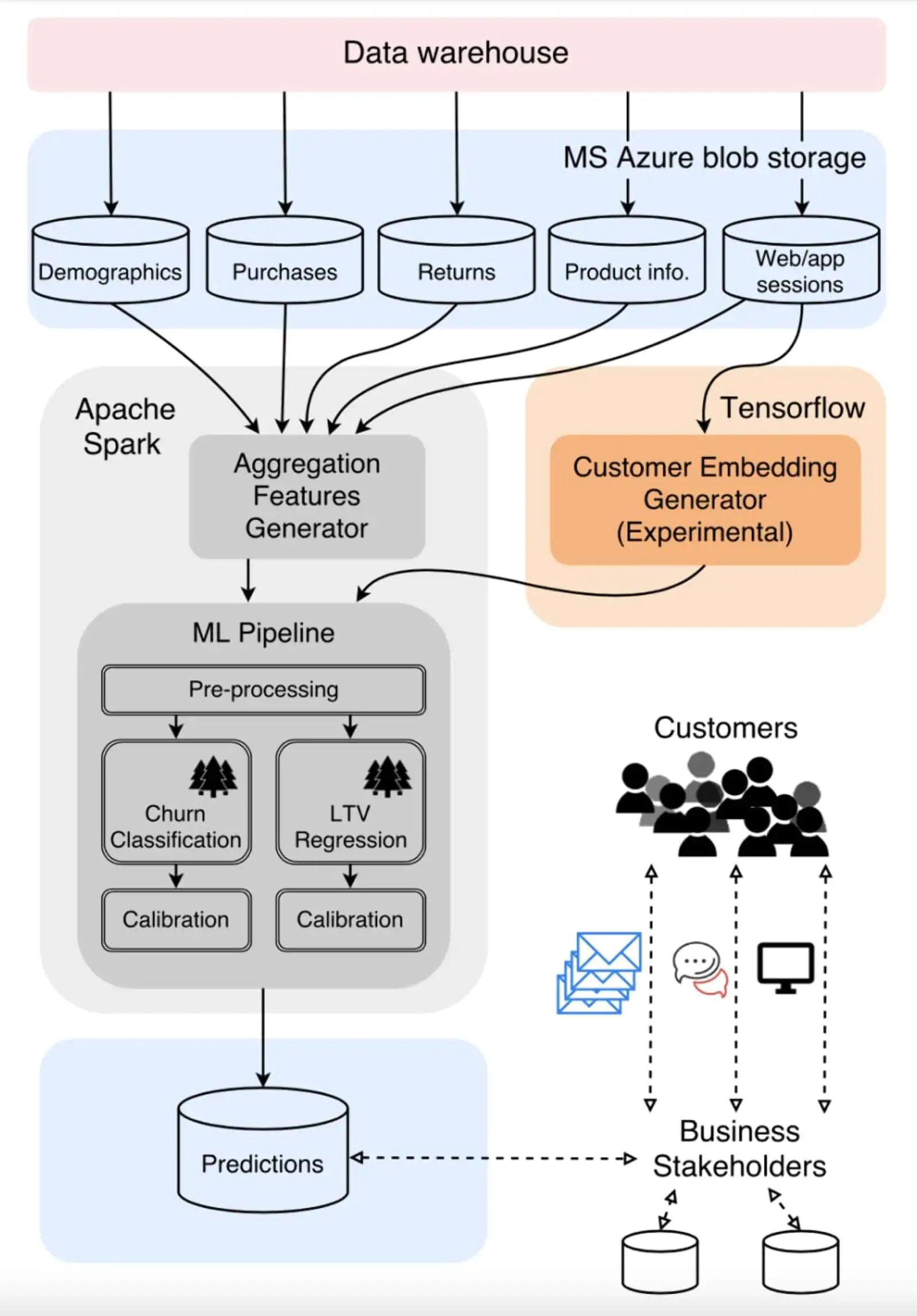
Архитектура данных для проекта ASOS
Особенности модели
В проекте для улучшения результатов прогнозирования используется принцип из обработки естественных языков (NLP): embeddings (внедрения, связки между элементами разной природы), который заключается в группировке слов, встречающихся в схожем контексте. Аналогичным образом происходит группировка покупателей по однотипности их интереса к товарам:
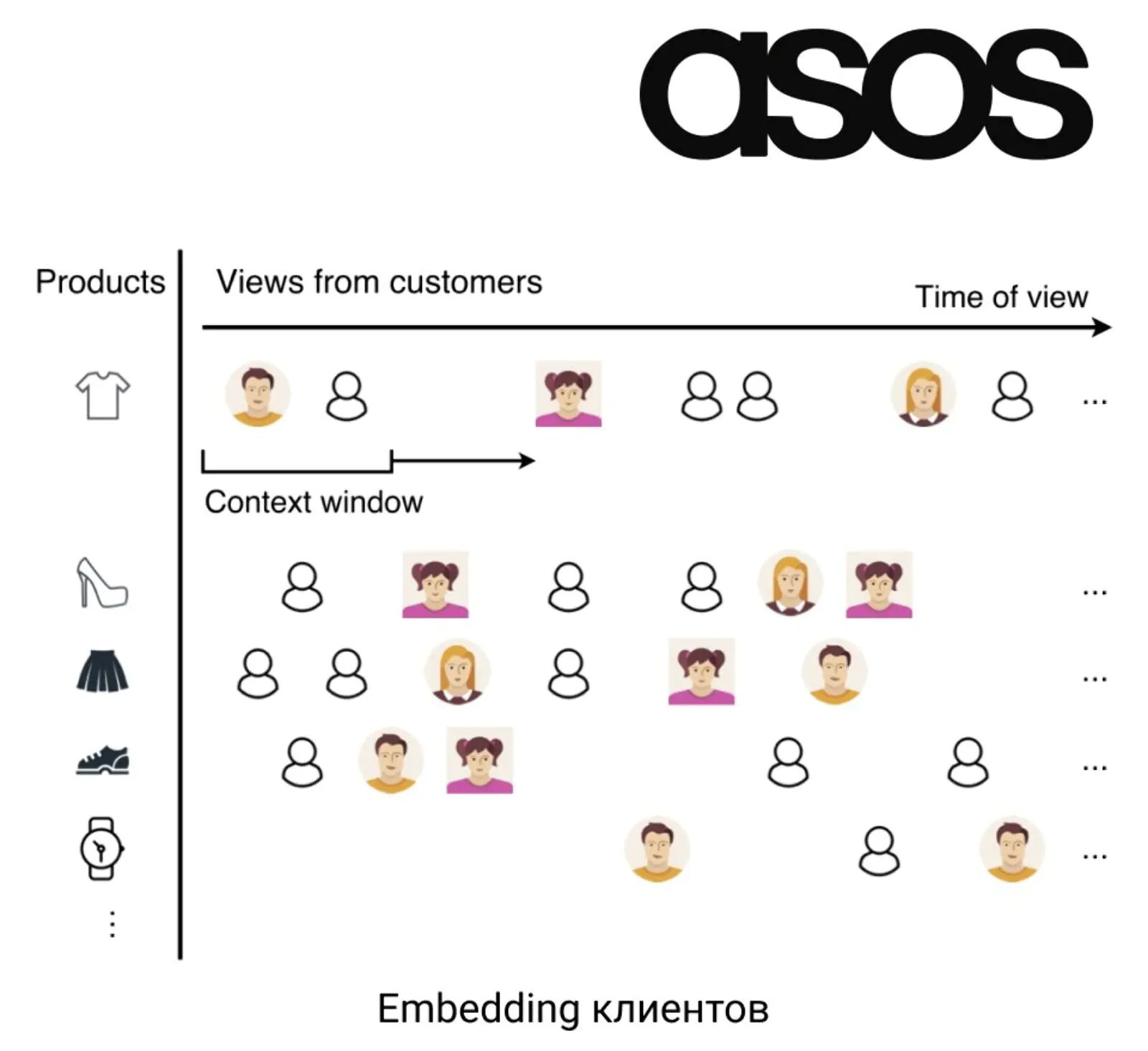
Пример эмбедингов для проекта ASOS
Каждая строка представляет продукт, продаваемый на ASOS, и последовательность просмотров этого продукта покупателями. Точное время просмотра продукта игнорируется. Клиенты, которые часто появляются в одном и том же контекстном окне, будут близки друг к другу.
В проекте ASOS пересекают между собой пользователей и продукты — такой подход часто называется «коллаборативной фильтрацией». Таким образом находят похожих друг на друга клиентов и через эмбеддинг в виде связки «продукт — пользователь» улучшают предсказание LTV.
Ключевые мысли
- Системный сбор данных, построение первой модели и расчет LTV — начало пути. После построения модели важно следить за чистотой данных (общие предпочтения клиентов, тип заказов, товарооборот, возвраты, бонусные счета) и контролировать обмен информации между сервисами (CRM-, CDP-системами, облачной базой данных, рекламными кабинетами и прочими). Потому что даже одно изменение этих данных или ошибка в обмене влияют на изменение LTV в целом.
- Необходимо постоянно отслеживать, учитывает ли текущая модель расчета все факторы, влияющие на LTV. Если нет, то надо дополнять модель новыми данными или даже в целом пересматривать методы оценки факторов.
Также рекомендуем управленческий мастер-класс Coffee Analytics, Mindbox и Benetton, где моделировалась кризисная ситуация падения дохода с клиента:
Презентация с мастер-класса об LTV на конференции «Полезный маркетинг»
Полный кейс Benetton
Комментарии экспертов

Три важных пункта, на которые стоит обратить внимание
- Сейчас большинство компаний используют валовый метод. Это просто формула, ее легко рассчитать. Если у вас данные уже собраны в одном месте, вы можете это сделать прямо сейчас.
- Статистические методы — это тоже по сути формулы, но чуть более сложные. Преимущества их в том, что от «средней температуры по больнице» мы переходим к более точным моделям.
- Машинное обучение необходимо для того, чтобы знать, сколько принесет конкретный клиент и что на это повлияет конкретно в вашем случае. Компании, которые выбрали этот метод, со временем смогут не только предсказывать, но и управлять этой метрикой.

У машинного обучения масса достоинств, среди которых — экономия времени сотрудников и избавление от ошибок, вызванных человеческим фактором. Считается, что эта технология доступна только промышленным гигантам из-за своей дороговизны. Однако опыт нашего клиента, обувной компании Mario Berlucci с 200 000 посетителей сайта в месяц, доказывает, что это не так.
В отделе data science Mario Berlucci пять сотрудников: аналитик, два специалиста data science, маркетолог и разработчик. Этого штата хватило, чтобы за полгода реализовать механику с предсказанием действий пользователей, которая приносит компании более 30% выручки. Помимо этого, бренд использует подразделение data science в паре с командой управления финансами: машинное обучение для бизнеса применимо много где, и не только в маркетинге.
Рекомендуем по теме
Изучить теорию и рассчитать LTV можно самостоятельно на курсах:
- A Definitive Guide for predicting Customer Lifetime Value (CLV) на Analytics Vidhya (открывается через VPN).
- Customer Lifetime Value Prediction with XGBoost Multi-classification на Towards data science.

