Статья будет полезна разработчикам, которые хотят найти новое применение нейросетям и разобраться в работе LSTM-модели.
24 февраля 2021
Как с помощью нейросети определить лучшую дату отправки email и повысить доход рассылки в 8,5 раз
Чтобы письма из email-рассылки не затерялись во входящих, а клиенты чаще их открывали и покупали товары, важно угадать правильное время отправки. С помощью нейросети мы проанализировали поведение клиентов и спрогнозировали дату отправки следующего email, чтобы порекомендовать клиенту товары в то время, когда он захочет их купить. Протестировали в зоомагазинах на рассылках с предложением повторной покупки и оценили результат с помощью AB-тестов. Получили следующие результаты:
-
в 23 разабольше целевых отправок email с помощью нейросети по сравнению с триггером
-
в 8,5 разувеличился доход от email-рассылки по атрибуции last click
-
в 2 разауменьшился процент отписок
-
в 17 развыросло число открытий в абсолютном значении
Статья будет полезна разработчикам, которые хотят найти новое применение нейросетям и разобраться в работе LSTM-модели, а также управленцам и маркетологам, которые хотят повысить доход email-канала. Ниже поделимся опытом и расскажем:
- почему решили использовать LSTM-модель нейросети для предсказания даты отправки email вместо алгоритма градиентного бустинга;
- как устроена LSTM;
- какие данные нейросеть использует для обучения;
- какую архитектуру нейросети использовали и с какими сложностями столкнулись;
- каких результатов достигли и как их оценивали.
Зачем предугадывать дату отправки email
Алгоритм Mindbox для определения лучшей даты отправки email — Next Best Action
Email-рассылки помогают рассказать клиентам о новинках, реактивировать уходящих в отток клиентов или показать персональные рекомендации. Для каждого клиента дата лучшей отправки писем разная: кто-то совершает покупки в выходные, поэтому лучше всего отправить письмо в субботу; а кто-то недавно купил домик для кошки, и стоит поскорее отправить письмо и посоветовать ему корм. Определить лучшую дату отправки email и угадать потребность клиента нам помогла нейросеть.
При этом наша задача не спамить и не перегружать клиентов рассылками, а направлять письма выборочно и дозировано. Алгоритм определяет, кому и когда отправить письмо, чтобы спрос и предложение совпали.
Например, клиент заказал в магазине корм и уходовые средства для собаки. Через какое-то время они кончатся и придется покупать новые. Чтобы не упустить этот момент, алгоритм рассчитывает, нужно ли направлять напоминание и когда это сделать. В письме клиент получит ссылку, по которой сможет повторить свой заказ. Так магазин сделает своевременное предложение, а клиент вовремя пополнит свои запасы и сэкономит время на поиски нужных товаров на сайте.
Почему решили отказаться от алгоритма на градиентом бустинге в пользу LSTM
Чтобы предугадать лучшую дату отправки email, сначала мы использовали стандартные алгоритмы. Целый год создавали признаки из истории действий клиентов и обучали на них градиентный бустинг, чтобы спрогнозировать лучшую дату отправки email. Например:
- рассчитывали, сколько дней пройдет с момента покупки до следующей покупки;
- пробовали сделать классификацию признаков и предсказать вероятность отправки письма в определенный день;
- пытались определить интересы пользователя в зависимости от места жительства, чтобы увеличить вероятность просмотра письма и кликов.
Но эта модель не давала стабильный положительный результат по всем компаниям, не могла находить сложные закономерности в поведении пользователей и не приносила достаточно денег.
Когда мы уже думали отказаться от алгоритма и идеи предсказать дату отправки email, решили попробовать что-нибудь экзотическое и обучить этой задаче LSTM-модель нейросети. Обычно её используют для анализа текста, реже — для анализа курса акций на финансовых рынках, но никогда в маркетинговых целях. И LSTM сработала.
Что такое LSTM
LSTM (Long Short Term Memory) — архитектура нейросетей, пришедшая из анализа естественного языка.
Разберем работу LSTM на примере машинного перевода. На вход нейросети по очереди подаются все буквы текста, а на выходе мы хотим получить перевод на другой язык. Чтобы перевести текст, сеть должна хранить информацию не только о текущей букве, но и о тех, что были перед ней. Обычная нейросеть не помнит, что ей показывали раньше, и не может сделать перевод всего слова или текста. LSTM, напротив, имеет специальные ячейки с памятью, где хранится полезная информация, поэтому выдает результат на основе суммарных данных и переводит текст с учетом всех букв в словах. Со временем нейросеть может очищать ячейки и забывать информацию, которая больше не нужна.
Такой же принцип оказался важен и для предсказания действий пользователя. Нейросеть учитывала всю историю действий и выдавала релевантные результаты — например, определяла лучшую дату отправки email.
Внутреннее устройство одного слоя LSTM
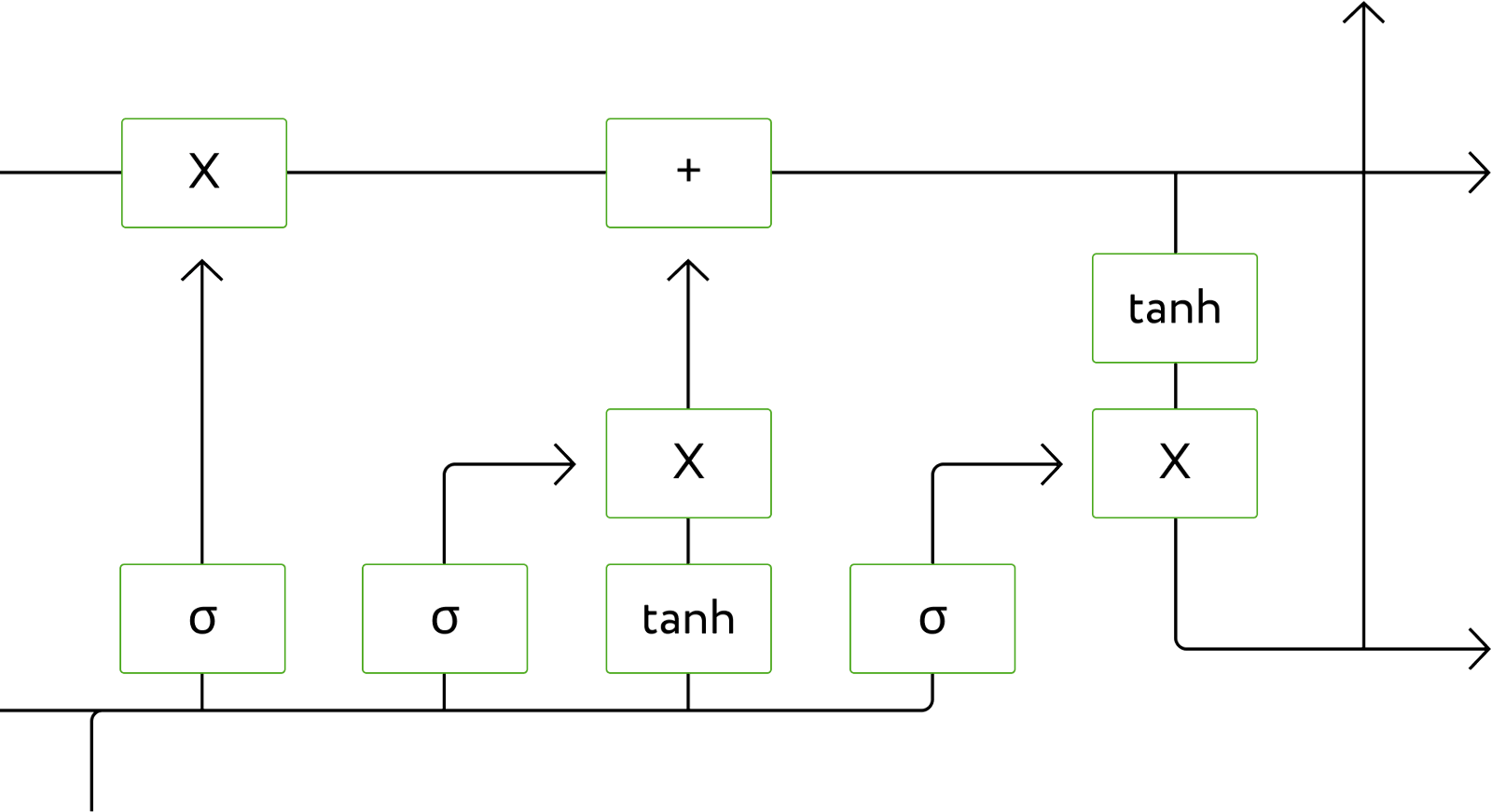
Внутренний слой LSTM состоит из операций сложения +, умножения ×, сигмоиды σ и гиперболического тангенса tanh
Какие данные использует нейросеть
Чтобы научиться прогнозировать лучшую дату отправки email, нейросеть анализирует набор исторических данных. Мы передаем в последовательность время, прошедшее между действиями, и 9 видов токенов:
- покупка дешевого товара,
- покупка товара средней цены,
- покупка дорогого товара,
- просмотр дешевого товара,
- просмотр товара средней цены,
- просмотр дорогого товара,
- получение письма,
- открытие письма,
- клик по любому объекту внутри письма.
Так выглядит типичный пример входной последовательности:
(view_medium, 0.5, view_cheap, 24, buy_cheap)
Пользователь с такой последовательностью посмотрел товар средней цены, через полчаса посмотрел дешевый товар, а еще через сутки решился и купил дешевый товар.
Последние пять действий пользователя — целевая переменная. Их нейросеть и научилась предсказывать.
Какую архитектуру нейросети применяли
В этом блоке технические нюансы для разработчиков. Если хотите перейти сразу к выводам, листайте дальше
Первые попытки обучить нейросеть были неуспешны: она переобучалась и всегда предсказывала только отправку письма, а не другие действия, например вероятность открытия письма или покупки. Так как клиенты чаще получают письма, чем открывают их или что-то покупают, «получение письма» — самый частый токен. Нейросеть получала по метрикам неплохие результаты, хотя реальный результат был негативным. Ведь нет смысла в алгоритме, который всегда говорит, что клиент получит письмо — и ничего больше.
Например, есть входная последовательность из трех токенов «получение письма» и одного «покупка товара». Нейросеть обрабатывает её и предсказывает последовательность с четырьмя токенами «получение письма». В 3 из 4 случаев она угадает, и клиент действительно получит письмо, но в таком предсказании нет смысла. Главная задача — предугадать, когда клиент откроет письмо и совершит покупку.
После проверки нескольких архитектур и способов обучения мы нашли то, что работает.
Seq2Seq (Sequence-to-sequence) — класс моделей машинного обучения, по которому одна последовательность преобразуется в другую на основе анализа прошлых действий
Как и обычно для Seq2Seq-моделей, сеть состоит из двух частей: энкодера и декодера. Энкодер небольшой и состоит из LSTM и embedding-слоев, а вот в декодере, помимо этого, используется self attention и dropout. В обучении мы используем teacher forcing — иногда даем предсказание сети в качестве входных данных для следующего прогноза.
Энкодер кодирует входную последовательность в вектор, который содержит важную, по мнению сети, информацию о действиях пользователя. Декодер, наоборот, декодирует полученный вектор в последовательность — это и есть предсказание сети.
Получение предсказания с помощью LSTM-сети
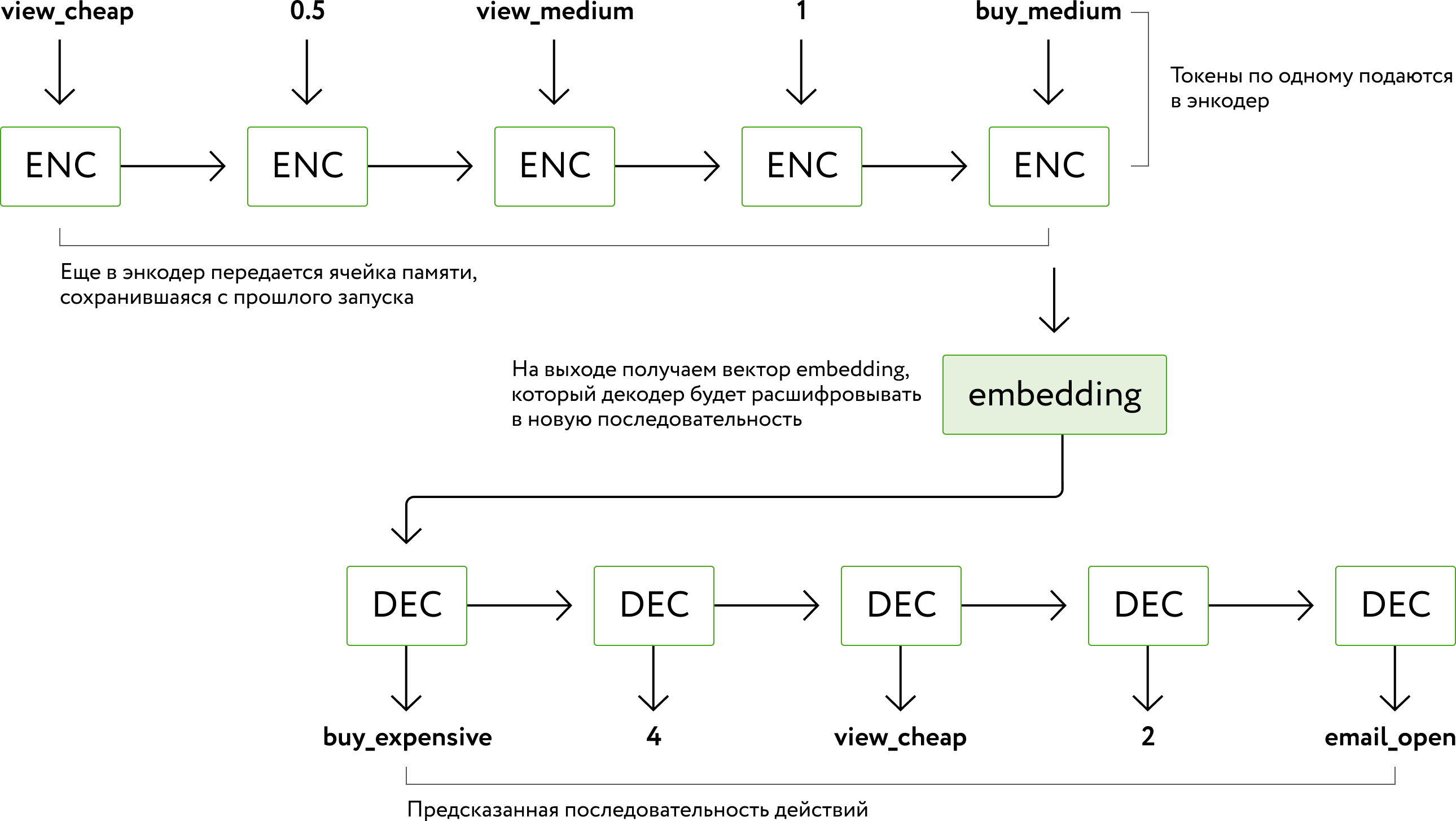
Время обучения: модель обучалась около суток на Tesla V100 и по завершении обучения получила ROC‑AUC 0.74.
Как LSTM-модель работает с реальными данными (инференс)
Чтобы применить модель для какого-нибудь пользователя и узнать, стоит ли отправлять ему письмо, соберем из его последних действий вектор и прогоним через нейросеть. Предположим, что ответ нейросети был такой:
(email_show, 10, email_open, 0.5, view_cheap, 0.5 view_medium, 15 buy_medium)
Модель предсказывает не только действия, но и сколько времени пройдет между ними. Обрежем все события, которые произойдут позже, чем через сутки. Их мы будем обрабатывать на следующий день, потому что за это время может появиться новая информация о действиях клиента, которую нужно будет учесть. Получим следующую последовательность:
(email_show, 10, email_open, 0.5, view_cheap, 0.5)
В последовательности есть токен просмотра, поэтому пользователю сегодня отправится письмо.
Важно отправлять письмо, только если есть токен просмотра или покупки, а не получения письма, чтобы сеть не повторяла триггерные рассылки, которые запомнила ранее. Например, если не учитывать просмотр и покупки, можем получить последовательность только с токенами получения письма. И тогда сеть продублирует триггерные настройки маркетолога вместо того, чтобы предсказать открытие письма или покупку:
(email_show, 10, email_show, 15, email_show, 0.5)
Как оценивали результат
AB-тесты проводили с клиентской базой зоомагазинов Бетховен и Старая ферма
Чтобы проверить работу модели, провели AB-тесты. В качестве baseline использовали алгоритм, который считает среднее время между покупками пользователя и отправляет email, когда это время проходит. Одна половина пользователей получила письма, исходя из решений baseline, другая — по предсказаниям модели.
Тест длился две недели и достиг статистической значимости. Нейросеть научилась находить в 23 раза больше пользователей, которым стоит отправить email, при этом в процентном соотношении open rate упал всего на 5%, а число открытий в абсолютных числах выросло в 17 раз.
Результат AB-теста для LSTM-модели нейросети и выводы

Так, эксперимент с нейросетью вместо алгоритма оказался успешным. LSTM-модель нейросети стала подходящим инструментом для предсказания лучшей даты отправки email. Мы на своем опыте поняли, что не нужно бояться использовать нестандартные модели для решения тривиальных задач.


